Applying Stephen Covey’s ‘Seven Habits of Highly Effective People’ to organisational functions
Vipin Luthra | January 23, 2022
")
In 2010, I attended a self-development program called ‘Seven Habits of Highly Effective People’. This program deeply impacted me, and I underwent a life-changing experience. Stephen Covey writes, “The way we see the problem is the problem.” We must allow ourselves to undergo paradigm shifts – to change ourselves fundamentally and not just alter our attitudes and behaviours on the surface. That's where the seven habits of highly effective people come in.
I was introduced to the three foundational fundamentals that impactful leaders adopt through this program.
One: they focus on personal effectiveness, also referred to as Private Victory or Self Mastery. This should be achieved first. The habits that help to accomplish this are “Be proactive”, “Begin with an end in mind”, and “Put the first thing first”. Earning trust and reliability are also the essential foundational elements for all human relationships. Habits 1, 2, and 3 focus on self-mastery and moving from dependence to independence.
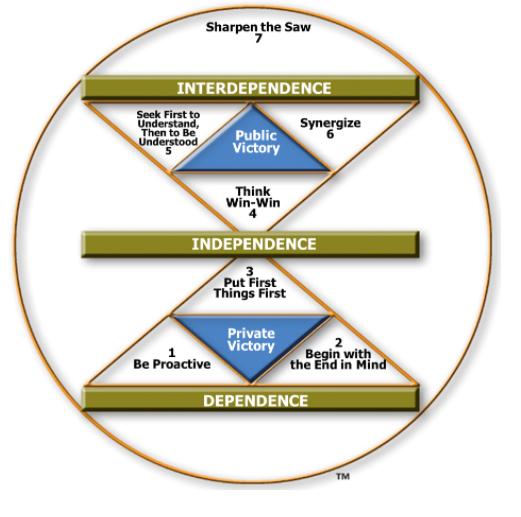 Two: they emphasise team effectiveness, also referred to as Public Victory (Working with others). The habits that help to accomplish this are “Think Win-Win”, "Seek first to understand, then to be understood", "Synergize". Habits 4, 5, and 6 focus on developing teamwork, collaboration, communication skills, and moving from independence to interdependence.
Two: they emphasise team effectiveness, also referred to as Public Victory (Working with others). The habits that help to accomplish this are “Think Win-Win”, "Seek first to understand, then to be understood", "Synergize". Habits 4, 5, and 6 focus on developing teamwork, collaboration, communication skills, and moving from independence to interdependence.
Three: continuous improvement is also referred to as “Sharpen the Saw”. Habit 7 is focused on continuous growth and advancement and embodies all other habits.
Meanwhile, let me talk about SRE – site reliability engineering – a topic very close to my heart. I have performed several roles in IT infrastructure and operations, designing applications, and developing codes in my career. The basic need of any organisation that aims for a digital transformation is the reliability of its IT infrastructure, including network stability and application resilience. I believe that reliability and trust are not only desirable human traits but are also necessary for machines and software engineering. This is an eternal truth – not something restricted to the domain of information technology alone.
What is SRE?
In 2013, Google coined the term SRE, and their goal was “Keeping Google up and running”. At Google, SRE is a practice of continually defining reliability goals, measuring those goals, and working to improve their services as needed. The main goals are to create scalable and highly reliable software systems.
How I see SRE through the prism of Seven Habits of Highly Effective People
As mentioned above, “Seven Habits of Highly Effective People” profoundly impacted me, and I started replicating this in my professional and personal space.
Let me elaborate.
Now let us try and see if we can extrapolate this and apply it in the wider organisational perspective.
Every organisation has IT functions and subfunctions.Let us start with the presumption that covey’s individual is a particular IT function of the organisation. Now let us apply all the seven habits to the organisational functions just as Covey applies them to individuals.
Step one – to make aparticular IT function effective (i.e., private victory)
Step two- to make all the different IT functions collectively effective (i.e., public victory)
Step three – continuously improve steps one and two
In the table below, let’s understand how organisations can adopt the SRE practices using the seven habits:
STEP ONE: TO MAKE A PARTICULAR IT FUNCTION EFFECTIVE (I.E., PRIVATE VICTORY)
*Begin with an end in mind.
This principle is focused on People Excellence within an IT function
It is imperative for any organisation to define its end goal to be achieved by the adoption of SRE. This should be followed by making their people understand what SRE means to them. Every IT function may have different objectives as part of SRE adoption that may ultimately map to the organisation’s goal. Hence, it is important to set the goals and expectations of every IT function for the adoption of SRE. They should have a shared sense of purpose and should develop an SRE mindset. Here are some examples of how various IT functions can develop a shared purpose.
1) “Design for Reliability”: It is important for the “Platform & Architecture” to design the application for reliability. The design includes all the IT infrastructure, networks, computes, databases, and applications for high availability and resilience. Fixing architectural mistakes becomes more difficult later in the development cycle
2) “Effective coding for Reliability”: Development teams should develop efficient code with an effectivetransaction logging framework, monitoring, alerting, and performance tuning. Effective transaction logging helps in the implementation of AI OPS and other predictive analytics tools.
3) “Monitoring Mindset to an observability one”: IT operations team should develop the observability mindset. Modern infrastructure has evolved from a monitoring mindset to an observability one. Observability as a mindset is the degree to which a team or company values the ability to inspect and understand systems, their workload, and their behaviour. Observability enables us to quickly and easily understand how the whole system runs—and even preempt issues.
Recommendation
An organisation should set up a centre of excellence for SRE. This team works closely with every function and helps them understand their role in adopting the SRE mindset and defines the objectives at the IT function level.Ultimately the goal should be that SRE becomes a part of every function in the organisation.
Be Proactive
This principle is focused on Product Excellence and enabling Intelligent and automated operations. Every IT function should focus on developing its capability to detect issues/problems proactively and fix them. Here are some examples.
Organisations should invest in the Implementation of end-to-endbusiness process monitoring solutions. This includes monitoring networks, compute, databases, application layer, integration layer, workloads,public URLs,etc. This should be followed by implementing self-healsolutionsthatmake necessary changes to restore themselvesto normal operations.
Organisations should also develop the Predictive AI Strategy and implement Predictive Analytical Toolsto harness predictive analytics. This willreduce operational inefficiencies and improve digital experiences. Predictive IT is a powerful new approach that uses machine learning (ML) and artificial intelligence (AI) to predict incidents before impacting customers and end-users.
Put the first thing first
This principle is focused on Process excellence, especially around alert management.
The team should understand what is important versus what is urgent.
This relates to excellence in the process, especially when it comes to alertmanagement.
Let’s try and map alert management to the four quadrants of time management.
1) Quadrant I: Urgent and important (Do): These are those alerts that must be fixed immediately
2) Quadrant II: Not urgent but important (Plan). These alerts are like warnings, may not be fixed on an urgent basis but should be actioned in due course of time, e.g., a continuous high CPU that may not be causing system downtime but can cause a major incident in the future.
3) Quadrant III: Urgent but not important (Delegate). These alerts may not be important for one team but need to be fixed byanothergroup. Hence, a hot handover is critical. E.g., it is essential to engage business on an urgent basis for any master data failure
4) Quadrant IV: Not urgent and not important (Eliminate). These are false alerts and act as a big noise that should be eliminated to increase effectiveness. I have seen a significant psychological impact on people’s minds when they receive too many false alerts. Generally, in such cases, the true alerts get misplaced, or the teamslose interest in taking adequate and timely action.
STEP TWO: TO MAKE ALL THE DIFFERENT FUNCTIONS COLLECTIVELY EFFECTIVE (I.E., PUBLIC VICTORY)
Think Win-Win
This habit focuses on cross-team excellence and on establishing shared metrics and alert thresholds across all the functions
Common metrics sources include:
•System metrics (CPU, memory, disk)
•Infrastructure metrics (Azure, AWS)
•Web tracking scripts (Google Analytics, Digital Experience Management)
•Application agents/collectors (APM, error tracking)
•Business metrics (Order to Cash, Load Out, Load In, etc.)
Here is an example: An application stops giving the precise performance if the CPU’s utilisation reaches above 95%, but the data centre compute team configures the high CPU threshold at 99%. There is a mismatch in setting the CPU’s utilization threshold by the application and infrastructure teams. The thresholds to be monitored should be standard across all functions.
Seek first to understand, then to be understood
This habit focuses on building better observable systems and the ability to quickly and easily understand how the whole system runs.This is achievable through the Three Pillars of Observability – Logs, metrics, and traces.
Observability is all about service reliability to provide the best customer experience. Observability is instrumenting your systems with tools to collect actionable data to know when errors occur. While having access to logs, metrics, and traces doesn’t necessarily make systems more observable, these are powerful tools that, if understood well, can unlock the ability to build better systems. Logs, metrics, and traces serve their unique purpose and are complementary. In unison, they provide maximum visibility into the behaviour of distributed systems.
"Synergize"
Synergize is the habit of creative cooperation. It is teamwork, open-mindedness, and the adventure of finding new solutions to old problems and managing the Error Budgets.
Various functions should work together to solve the alerts and major incidents and follow common approaches to platforms for solving problems, focusing on solving more complex problems. And to maintain effective relationships among various steams and with their different partner teams. Effective communication is a high priority in SRE.
Under this habit, Stephan Covey also talks about the Emotional Bank Balance. This is very much like a checking account at a bank. You can make deposits, improve the relationship, or take withdrawals and weaken it.
Similarly, organizations can spend their error budget in any way they like. If the product is currently running flawlessly, they can launch any innovations with few or no errors. Conversely, suppose they have met or exceeded the error budget and are operating at or below the defined SLA. In that case, all innovations or launches are on hold until they reduce the number of errors to a level that allows the launch to proceed.
STEP THREE: CONTINUOUSLY IMPROVE STEPS ONE AND TWO
Sharpen the saw
“We must never become too busy sawing to take time to sharpen the saw.”
–Dr. Stephen R. Covey
This habit focuses on governance and measuring the Key Performance Indicators. This helps the organisations measure where they are today and continuously improve and ensure that they are moving in the right direction to achieve their goal towards the adoption of the SRE principles.
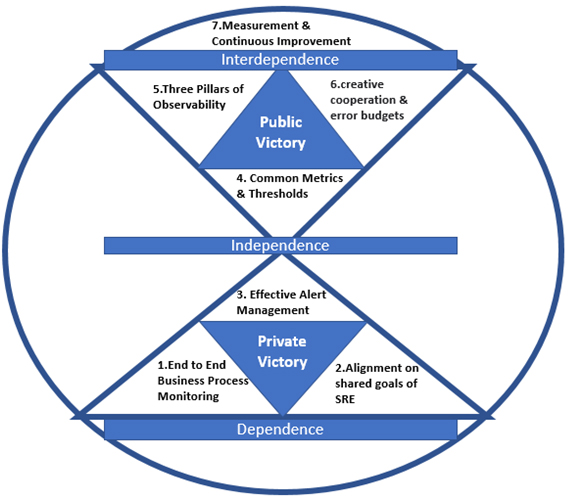
The above diagram shows the Maturity Continuum of the SRE. In this way, any organization can fulfill its dream of adopting SRE by following the seven habits of Dr Stephan Covey.
P.S.: A couple of years ago, I was asked to lead IT operations of the ‘Go To Market’ area that had many challenges related to system reliability and availability. I tried to apply all these principles and achieved fantastic results. I will share those details with you in my upcoming blogs.
Let me know how your organisations are embarking on their journey of SRE adoption.
Ms. Vipin Luthra is a highly respected IT leader with nearly 25 years of experience. She hails from Roorkee in Uttarakhand and is a graduate of the IIT Roorkee. Currently, she is working as Senior Director in PepsiCo.
The union cabinet chaired by PM Narendra Modi has approved the Mobile Phone Manufacturing Scheme (MPMS) with a budgetary outlay of Rs 62,500 crore. It aims to further scale up the production, deepen domestic value addition, strengthen supply chain resilience, enhance global competitiveness. It
Recent stories of stolen railway wires, disappearing communication towers and missing public infrastructure are often treated as bizarre law-and-order failures of India. Yet they raise a more fundamental question. Why does the State often discover the disappearance of a public asset only after it has alrea
India appears to be investing fresh dynamism in its Indo-Pacific strategy. At the time when the US, under president Donald Trump, has adopted a conciliatory approach towards China and has changed the name of America’s Indo-Pacific Command to just Pacific Command, India has quietly moved towards con
Maharashtra`s fiscal management has come under sharp scrutiny after the Comptroller and Auditor General (CAG) of India, in its State Finances Audit Report for 2024-25, flagged significant budgetary inefficiencies, accounting irregularities, understatement of key fiscal indicators and widespread governanc
Some neglect is loud. This kind is quiet. It sits in research never commissioned, data never collected, questions never asked. In South Asia, that quiet has let the region’s worst health problems stay understudied, underfunded, and out of sight of those who could act.
Mumbai Metro Line 3 (Aqua Line), the city`s first fully underground metro corridor and one of its largest public transport investments, represents a major engineering achievement and has been widely welcomed by commuters. However, the overall commuter experience continues to be constrained by accessibili













